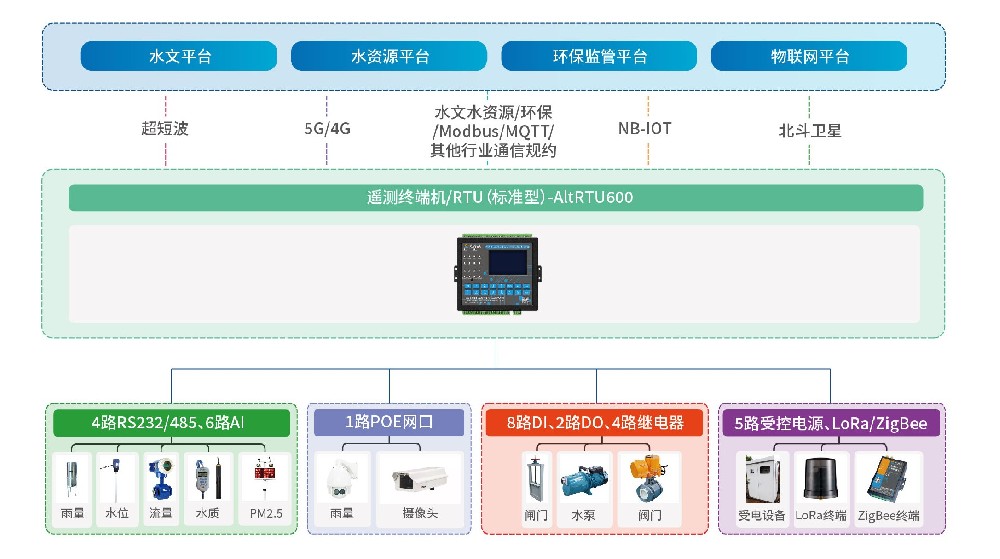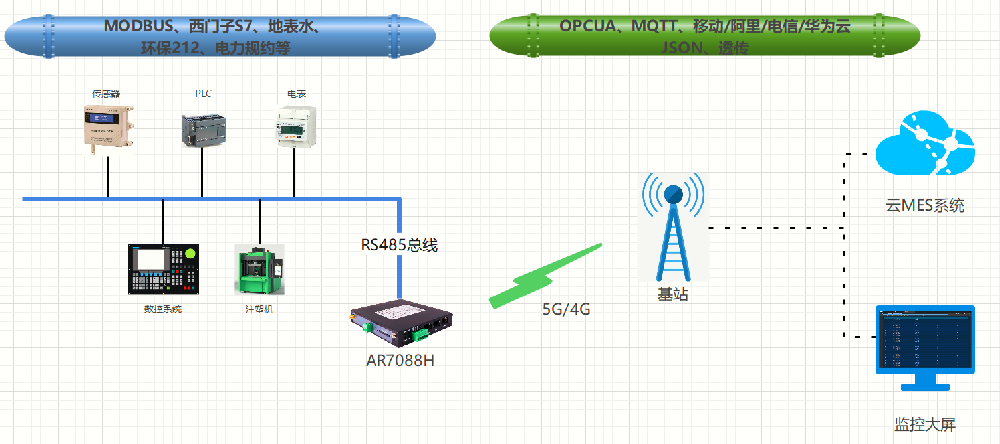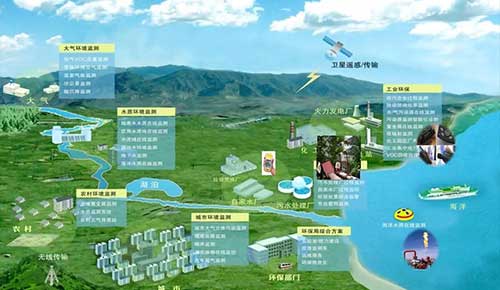

双5G边缘计算网关/工业CPE-AR7091G/GK
AR7091G/GK——基于5G/4G/3G/2G、WiFi、虚拟专网等技术开发的工业物联网边缘网关/CPE。产品采用高性能的工业级32位通信处理器和工业级无线模块,以嵌入式操作系统为软件支撑平台,可同时连接串口设备、以太网设备和 WiFi 设备, 支持内部Flash和外扩Micro SD卡存储数据,能满足工业现场通信的需求。

 电力国产化崛起!爱陆通赋能电力智能化升级
电力国产化崛起!爱陆通赋能电力智能化升级
 无人码头数据终端是什么原理?
无人码头数据终端是什么原理?
 集中式DTU通信解决方案-智能配网
集中式DTU通信解决方案-智能配网
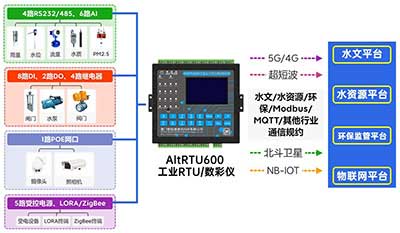 5G视频RTU 视频数采仪 数据采集传输仪
5G视频RTU 视频数采仪 数据采集传输仪

分布式DTU快盈500是一种创新的数据处理技术,其核心在于将原本集中处理的数据任务分散到多个独立的节点(通常是高性能计算机或服务器)上执行。这种分布式架构不仅能够有效应对海量数据的处理挑战,还极大地提升了系统的灵活性和扩展能力。每个节点作为数据处理的一个单元,既独立工作又相互协作,共同完成复杂的数据处理任务。
快盈5001. 可扩展性: 面对不断增长的数据量,分布式DTU展现出了强大的适应能力。通过简单地增加节点数量,系统可以轻松扩展处理能力,确保无论数据量多么庞大,都能得到及时有效的处理。这种灵活的扩展机制,为企业应对未来数据增长提供了坚实的保障。
2. 高效率: 分布式DTU采用并行处理策略,将任务分割成多个子任务,并在多个节点上同时执行。这种“分而治之”的方法显著提高了数据处理速度,特别是在处理大规模数据集时,其效率优势尤为明显。对于时间敏感型应用,如实时数据分析,分布式DTU无疑是最佳选择。
快盈5003. 可靠性: 分布式系统的核心优势之一在于其冗余设计。在分布式DTU架构中,每个节点都承担着一部分数据处理任务,且节点之间通常存在数据备份或任务复制机制。因此,即使某个节点发生故障,其他节点也能迅速接管其任务,确保数据处理过程不受影响,从而大大提高了系统的可靠性和稳定性。
快盈5004. 广泛的应用性: 分布式DTU不仅适用于数据分析、数据挖掘等传统数据处理领域,还能很好地支持机器学习、人工智能等新兴技术的数据处理需求。其强大的通用性和灵活性,使得它能够在金融、医疗、物联网、智能制造等多个行业发挥重要作用。
快盈5001. 大数据处理: 在大数据时代,单个节点处理海量数据的能力有限。分布式DTU通过构建庞大的计算网络,轻松应对PB级甚至EB级数据的处理需求,为大数据分析提供了强大的技术支持。
快盈5002. 计算密集型任务: 对于需要大规模计算资源的任务,如基因测序、天气预报、复杂模型模拟等,分布式DTU通过并行计算,将计算任务分散到多个节点上执行,显著缩短了计算周期,提高了计算效率。
3. 高可用性需求: 在金融交易、在线服务、关键基础设施监控等场景中,系统的连续运行至关重要。分布式DTU通过冗余设计和故障切换机制,确保了即使在最恶劣的条件下,也能提供不间断的服务,满足了高可用性需求。
快盈5004. 分布式存储配合: 随着分布式存储技术的普及,如Hadoop HDFS、Ceph等,分布式DTU与这些存储系统的结合,实现了数据的分布式存储与分布式处理的完美融合,进一步提升了数据处理的整体效能。
1. 数据采集: 这是数据处理的起点,通过部署在现场的传感器、物联网设备等,实时或定期采集各类数据,并将其暂存于本地存储设备中。
快盈5002. 数据聚合: 采集到的原始数据往往杂乱无章,需要进行预处理。数据聚合阶段,系统会对数据进行清洗、格式化、分组等操作,为后续处理奠定基础。
3. 数据传输: 经过聚合的数据,通过高速网络或专用通信介质,安全、高效地传输到分布式系统中的各个目标节点。这一过程要求数据传输协议的高效性和安全性。
4. 数据处理: 目标节点接收到数据后,根据具体任务需求,进行计算、存储、转换等操作。这一阶段是分布式DTU发挥并行处理优势的关键。
5. 数据分析: 最后,利用先进的数据分析工具,如Python、R语言、Spark等,对处理后的数据进行深度挖掘和分析,提取有价值的信息和洞察,为决策支持提供依据。